




I’ve spent the better part of my career in the trenches of enterprise architecture, wrestling with the messy realities of building systems that have to actually work, at scale, under fire. And as I watch the industry’s current obsession with agentic AI, I see a familiar and dangerous pattern emerging. Everyone is captivated by the capabilities of Large Language Models (LLMs) – their remarkable ability to reason, plan, and use tools. The conversation is dominated by prompt engineering, model fine-tuning, and demos of single agents performing clever tricks on a developer’s laptop.
This is a profound misdirection.
Let me be blunt: while the intelligence of agentic AI is impressive, the truly hard part lies in building the robust, production-grade distributed systems required to support and scale it. Moving from a single-agent proof-of-concept to a swarm of autonomous agents executing complex, long-running tasks inside a real enterprise forces us to confront the most brutal problems in our field: state consistency, fault tolerance, coordination, and governance across a fallible network.
We’ve fought these battles for decades with service-oriented architectures and microservices. But agentic AI adds a terrifying new variable to the equation: non-determinism. An agent’s “failure” isn’t just a network timeout or a null pointer exception. It can be a logical error, a hallucinated fact, a poorly reasoned decision, or a subtle goal misalignment that leads to catastrophic business outcomes. This isn’t just a bug; it’s a failure of cognition. This fundamentally changes how we must architect for resilience and predictability.
This is a call to action for my fellow architects. Our job is to look past the hype and bring the battle-tested principles of distributed systems engineering to the table. We need to start modeling these new entities to represent them as a Business Role when they replace human functions or an Application Component when they are purely technical, ensuring they are always tied back to concrete business objectives. The hype cycle will fade, but the systems we build will remain. And their success or failure will depend not on the cleverness of the prompts we write, but on the soundness of the architecture we design. The real work is just beginning.
1. Deconstructing the Agentic Monolith: Architectural Patterns and Their Scars
When we start building with agentic AI, we don’t jump straight into a self-organizing swarm. That’s a recipe for disaster. In my experience, successful adoption follows an evolutionary path, a continuum of increasing complexity and autonomy. Each step on this path introduces new capabilities but also new architectural trade-offs and new scars.
The Spectrum of Agentic Design
Level 1: Deterministic Chain (e.g., Basic RAG)
---
config:
theme: 'base'
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
subgraph "Deterministic Chain"
direction LR
Input1[Input] --> Retrieve --> Augment[Augment] --> Generate[Generate] --> Output1[Output]
end
class Retrieve,Augment,Generate main
This is the entry point. A fixed, predictable workflow, often called a “Chain”. For a Retrieval-Augmented Generation (RAG) system, this means the flow is always the same: retrieve relevant documents from a vector index, augment the user’s prompt with that context, and generate a response from the LLM. There is no dynamic decision-making. It’s predictable, easy to debug, and perfect for well-defined, repeatable tasks. But it’s brittle. It breaks the moment it encounters a novel situation that doesn’t fit its rigid, pre-programmed path.
Level 2: Single Agent (Tool-Use)
---
config:
theme: 'base'
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
subgraph "Single Agent (Tool-Use)"
Agent
subgraph Tools
direction LR
Tool1[API Call]
Tool2
Tool3[Vector Index]
end
Agent -->|decides to use| Tool1
Agent -->|decides to use| Tool2
Agent -->|decides to use| Tool3
end
class Agent main
This is the next logical step and, frankly, the sweet spot for many initial enterprise use cases. Here, a single agent uses an LLM’s reasoning capabilities to dynamically decide which tools to call, and in what order, to accomplish a goal. These tools aren’t just for data retrieval; they are actions – APIs to update a CRM, functions to send an email, or queries to a SQL database. This pattern offers a powerful combination of flexibility within a contained, observable boundary. However, it’s still a monolith in terms of reasoning. The single agent is a bottleneck. It can’t perform multiple complex tasks in parallel, which limits its ability to solve problems that require a divide-and-conquer strategy.
Level 3: Multi-Agent System
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
subgraph "Multi-Agent System"
Planner -->|decomposes task| SubAgent1
Planner -->|decomposes task| SubAgent2
end
class Planner mains
This is the frontier, where the real distributed systems pain begins. When a task is too complex or requires diverse expertise, we decompose it and assign the pieces to a team of specialized agents. This is where we must make fundamental architectural choices about how these agents collaborate.
Multi-Agent Collaboration Patterns
Orchestrator-Worker
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
O[Orchestrator Agent]
W1[Worker Agent 1]
W2[Worker Agent 2]
W3[Worker Agent 3]
O -->|dispatches task| W1
O -->|dispatches task| W2
O -->|dispatches task| W3
class O main
This is a classic and powerful pattern. A central “commander” or “planner” agent decomposes a high-level goal into sub-tasks and dispatches them to specialized “worker” agents that can execute in parallel. We see this pattern in sophisticated implementations like Anthropic’s research system, where a LeadResearcher agent coordinates multiple subagents to explore different facets of a query simultaneously. The primary benefit is centralized control; the orchestrator has a holistic view of the plan, making the workflow easier to trace and manage. The massive trade-off, as with any centralized controller, is that the orchestrator is both a single point of failure and a potential performance bottleneck. If the orchestrator stalls, the entire process grinds to a halt.
Decentralized Choreography (e.g., “Group Chat”)
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
EB((Event Bus))
DA1[Agent A] -->|publishes event| EB
DA2 -->|publishes event| EB
EB -->|event consumed| DA3[Agent C]
EB -->|event consumed| DA4
class EB main
In this model, there is no central brain. Agents communicate in a shared environment, such as a “group chat” or an event stream, reacting to each other’s messages and emergent events. This pattern offers maximum scalability and resilience. With no single point of failure, the system can tolerate the loss of individual agents. However, it is an absolute nightmare to debug, govern, and comprehend. Trying to trace a single business transaction through this web of asynchronous messages is like trying to reconstruct a conversation from scattered whispers in a crowded room. Control is emergent, not explicit, which can be terrifying in a compliance-heavy enterprise environment.
Hierarchical Pattern
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
TLA((Top-Level Agent))
MLA1[Mid-Level Agent 1]
MLA2[Mid-Level Agent 2]
H_W1[Worker A]
H_W2
H_W3[Worker C]
TLA --> MLA1
TLA --> MLA2
MLA1 --> H_W1
MLA1 --> H_W2
MLA2 --> H_W3
class TLA main
This is essentially a recursive application of the orchestrator-worker pattern. A top-level agent orchestrates a team of mid-level agents, each of which, in turn, orchestrates its own team of worker agents. This allows for the decomposition of extremely complex problems into manageable sub-trees. While powerful, it doesn’t eliminate the core challenges; it multiplies the coordination complexity at each layer of the hierarchy.
The Event-Driven Transformation
A critical architectural decision that cuts across these patterns is the communication mechanism. Direct, synchronous request/response calls between agents are a path to ruin. They create tight coupling; Agent A needs to know the network address and specific API of Agent B. If Agent B is slow or fails, Agent A is blocked, leading to cascading failures.
The superior approach is to build the system on an event-driven backbone. Instead of Agent A calling Agent B directly, Agent A produces an event – a fact, like TaskCreated – to a durable, distributed log like Apache Kafka. Agent B, as part of a consumer group, subscribes to that event stream and processes the event when it’s ready.
This is not a minor implementation detail; it is a fundamental architectural transformation. It decouples the agents, allowing them to operate asynchronously and independently. This immediately provides enormous operational benefits:
- Scalability: Need to process tasks faster? Simply add more worker agents to the consumer group. The Kafka rebalance protocol will automatically distribute the workload.
- Resilience: If a worker agent crashes, its work partitions are automatically reassigned to a healthy agent in the group. The orchestrator doesn’t even need to know it happened.
- Fault Tolerance: The immutable log of events serves as the system’s source of truth. If a downstream system needs to be rebuilt or a failed process needs to be recovered, you can replay the events from a specific offset.
Adopting an event-driven architecture is a foundational necessity for building serious multi-agent systems. It’s the difference between a brittle prototype that works on a good day and a production system that can withstand the chaos of the real world.
To help guide this decision, the following table summarizes the trade-offs of these architectural patterns. An architect’s job is to make informed compromises, and this provides a framework for choosing which kind of pain you’re willing to accept for your specific use case.
| Pattern | Description | Best For | Key Trade-offs (Complexity, Scalability, Control, Debuggability) |
|---|---|---|---|
| Deterministic Chain | Fixed, predictable workflow. No dynamic decisions. | Simple, well-defined tasks (e.g., basic RAG). | Low Complexity, Poor Scalability for dynamic tasks, High Control, High Debuggability. |
| Single Agent (Tool-Use) | One agent, dynamic tool selection based on reasoning. | Contained but flexible single-domain tasks. | Moderate Complexity, Limited Scalability (single-threaded reasoning), High Control, Moderate Debuggability. |
| Orchestrator-Worker | Central agent dispatches tasks to parallel workers. | Complex, decomposable problems requiring coordination. | High Complexity, Good Scalability (of workers), Centralized Control, Lower Debuggability (tracing across workers). |
| Decentralized (Choreography) | Agents react to events; no central control. | Highly dynamic, emergent systems where autonomy is key. | Very High Complexity, Maximum Scalability, Low/Emergent Control, Very Low Debuggability. |
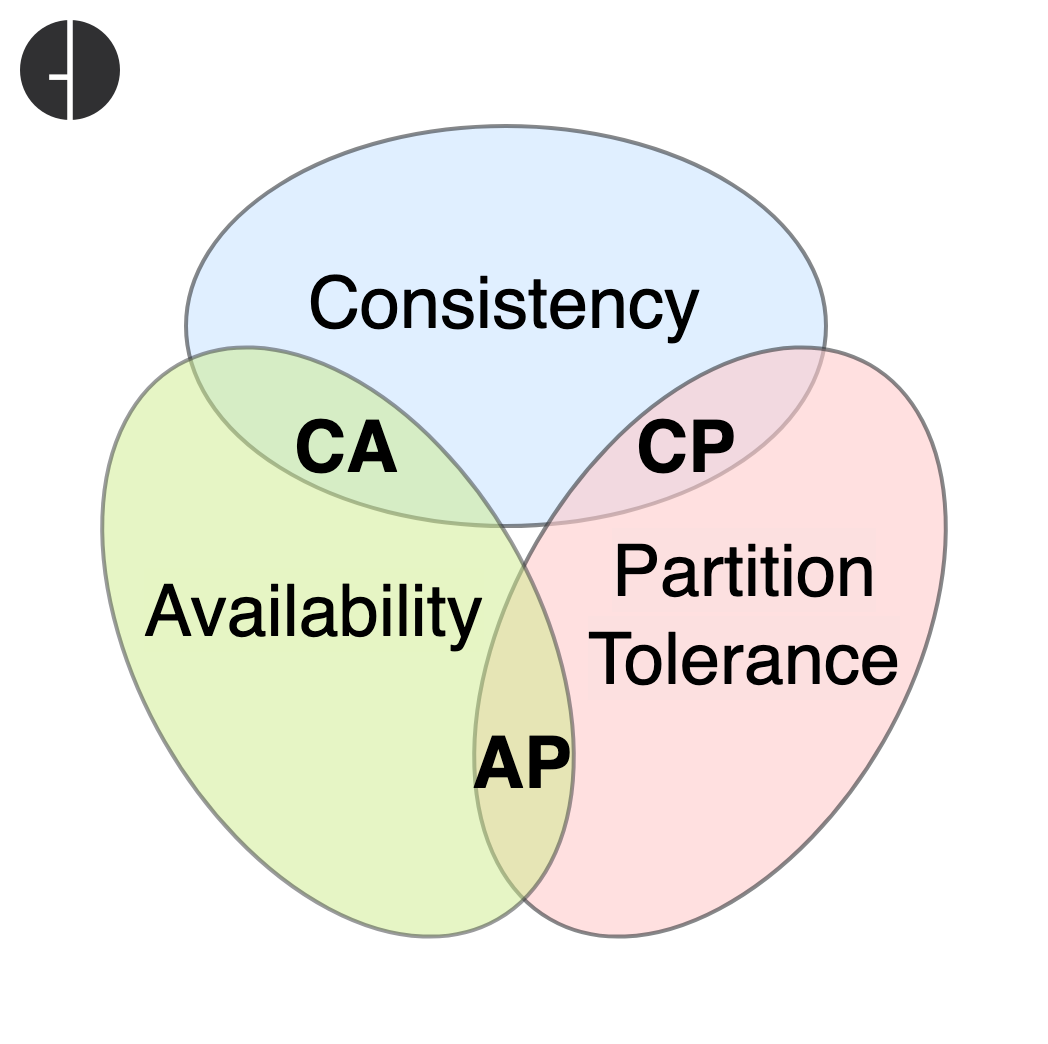
2. The State of State: Why the CAP Theorem Is More Relevant Than Ever
Now we arrive at the most fundamental problem in all of distributed computing: managing state. An agent without memory is useless. It cannot learn, it cannot maintain context, and it cannot execute any task that requires more than a single step. But this “memory” isn’t just the context window of an LLM call. It’s the persistent state of a business process that might span hours, days, or even weeks. What happens if the server hosting your agent reboots halfway through processing a multi-million-dollar order?
This forces us to confront Brewer’s CAP Theorem. As a quick refresher, the theorem states that in any distributed data store, you can only have two of the following three guarantees: Consistency, Availability, and Partition Tolerance. Since network partitions (P) are a given in any real-world system, the architect’s true choice is between Consistency (C) and Availability (A).
This isn’t an academic exercise; it has profound implications for how our agents behave.
In the presence of a Network Partition (P)
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
P[P: Network Partition Occurs] --> G{Must Choose Between C and A};
G --> CP;
G --> AP;
class P main
A CP Agent System (Consistency over Availability)
In this model, correctness is king. If an agent cannot communicate with its authoritative data store to guarantee it has the most recent, correct state, it simply stops processing. It becomes unavailable. This is the only acceptable model for use cases where acting on stale or incorrect data would be catastrophic – think financial transactions, medical diagnostics, or regulatory compliance checks. The trade-off is stark: your system is correct, but it can grind to a halt.
---
config:
theme: "base"
---
sequenceDiagram
autonumber
participant Agent
participant DataStore
participant Result
Agent->>DataStore: Request Data
Agent-->>DataStore: ❗ Network Partition
Agent->>Result: Halts Processing
An AP Agent System (Availability over Consistency)
Here, the priority is to always provide a response. If the primary state store is down, the agent proceeds with whatever data it has, even if it’s a locally cached, potentially stale version. The system remains available during partitions. This is acceptable, and often desirable, for use cases like product recommendations or news summarization, where a slightly outdated answer is far better than an error message. The system is more resilient, but it comes at the cost of potential inconsistency.
---
config:
theme: "base"
---
sequenceDiagram
autonumber
participant Agent
participant DataStore
participant LocalCache
participant Result
Agent->>DataStore: Request Data
Agent-->>DataStore: ❗ Network Partition
Agent->>LocalCache: Falls back to
LocalCache-->>Agent: ❗ Provides Stale Data
Agent->>Result: Responds
Agent Memory
The crucial realization is that an agent’s state is not monolithic. We often talk about “agent memory” as a single concept, but in a real enterprise architecture, it’s a composite of different types of state with different consistency requirements. An agent has:
- Short-Term Memory: The context of the current task or conversation, often managed in-memory.
- Long-Term Memory: The vast repository of knowledge the agent draws from, typically stored in a vector database for retrieval.
- Transactional State: The record of the current step in a long-running business process, like “payment processed, awaiting shipping confirmation.”
These different types of state demand different CAP trade-offs. The transactional state for an insurance claim agent must be strongly consistent (CP). The long-term knowledge base it pulls from can likely be eventually consistent (AP); it’s okay if it doesn’t have the absolute latest document for a few seconds.
Therefore, we must move beyond a simple “CP vs. AP” choice for the entire system and architect for a hybrid state model. A single agent will need to interact with multiple data stores, each with different consistency guarantees. The agent’s own logic must be consistency-aware, knowing which data sources provide an unimpeachable source of truth and which might be slightly stale. This requires a level of sophistication in our data architecture that most agentic AI discussions completely ignore.
Embracing Failure: The Saga Pattern for Resilient Agentic Workflows
Failure is not an exception; it is an inevitability. In a multi-agent system executing a complex business process – like processing an insurance claim or managing supply chain logistics – a step can fail for a dizzying number of reasons. A required tool API might be down, the input data could be malformed, or, most uniquely to our domain, the agent might simply make a bad decision. In these long-running, multi-step processes, we can’t just lock all the resources for hours and hope for the best. A simple retry loop is dangerously naive. We need a robust mechanism to gracefully undo what has already been done.
The canonical solution for this problem is the Saga pattern. A Saga manages a distributed transaction as a sequence of local transactions. Each successful step triggers the next step in the sequence. If any local transaction fails, the Saga executes a series of compensating transactions in reverse order to undo the work of the preceding steps. This allows us to maintain data consistency across services without using brittle, blocking mechanisms like two-phase commit.
Like our multi-agent architectural patterns, Sagas can be implemented in two primary ways:
Orchestration-based Saga
A central Saga orchestrator (which could be an agent itself) acts as the state machine for the business process. It explicitly sends commands to each agent or service to perform a task. If a step fails, the orchestrator is responsible for calling the corresponding compensation actions in the correct order. This approach is far easier to understand, monitor, and debug because the entire business logic is centralized. The downside is that the orchestrator becomes a single point of failure and a potential scalability bottleneck.
---
config:
theme: "base"
---
sequenceDiagram
autonumber
participant Orchestrator
participant OrderService
participant PaymentService
Orchestrator->>OrderService: CreateOrder
OrderService-->>Orchestrator: OrderCreated
Orchestrator->>PaymentService: ProcessPayment
PaymentService-->>Orchestrator: ❌ PaymentFailed
Orchestrator->>PaymentService: CompensatePayment
Orchestrator->>OrderService: CompensateOrder
Choreography-based Saga
There is no central controller. Each agent or service subscribes to events published by its peers. Upon receiving an event (e.g., OrderPaid), a service executes its own local transaction and then publishes its own event (ItemsShipped). Compensation is also handled via events (PaymentFailed triggers a CancelOrder event). This approach is loosely coupled, highly scalable, and resilient. However, it can become incredibly difficult to determine the overall state of a business process, as the logic is spread across many independent components.
---
config:
theme: "base"
---
sequenceDiagram
autonumber
participant OrderService
participant PaymentService
participant EventBus
OrderService->>EventBus: Publishes 'OrderCreated'
EventBus-->>PaymentService: Consumes 'OrderCreated'
PaymentService->>EventBus: Publishes 'PaymentFailed'
EventBus-->>OrderService: Consumes 'PaymentFailed' & Compensates
The introduction of autonomous agents, however, adds a new layer of complexity to this pattern. In traditional Sagas, compensating actions are deterministic and technical. The compensation for ChargeCreditCard is RefundCreditCard. The compensation for ReserveInventory is ReleaseInventory. But what is the compensation for an agentic action?
If an agent’s task was, “Draft a personalized apology email to the customer explaining the shipping delay,” you can’t simply “un-draft” it. If an agent’s action was, “Re-route our entire shipping fleet based on a dynamic weather forecast,” and that forecast turns out to be wrong, the compensation is not a simple rollback. The compensation is another complex, goal-oriented task: “Calculate a new optimal route based on the updated information and communicate the changes to all drivers.”
This means that for agentic systems, the Saga pattern must evolve. Compensating actions are no longer just simple technical rollbacks; they are semantic, goal-oriented tasks that may require another complex, reasoned agentic process to execute. Our Saga orchestrator or event flow must be capable of invoking other agents as part of its failure handling logic. This deeply intertwines the system’s fault-tolerance mechanism with the agents’ core reasoning capabilities, a connection that demands careful architectural consideration from day one.
3. The Ghost in the Machine: Concurrency, Communication, and the Actor Model
As we scale our systems to hundreds or thousands of agents operating in parallel, we face another classic distributed systems challenge: concurrency. How do we prevent these agents from tripping over each other, deadlocking, or corrupting shared state? Traditional concurrency models that rely on shared memory and locks are a well-known source of complexity and bugs, and they are a particularly poor fit for a system of distributed, autonomous agents. We need a computational model that embraces isolation and asynchronous communication by design.
For this, I have found the Actor Model to be an exceptionally powerful paradigm. Its core principles map almost perfectly to the requirements of a multi-agent system:
- Everything is an Actor: An actor is a fundamental unit of computation. It’s a lightweight process that bundles state and behavior together – a perfect abstraction for an AI agent.
- Encapsulated State: An actor’s internal state is completely private. It cannot be accessed or modified directly by any other actor. This is the model’s superpower: it eliminates the possibility of data races and the need for locks by design.
- Asynchronous Message Passing: Actors communicate with each other exclusively by sending immutable, asynchronous messages to each other’s “mailboxes.” A sender sends a message and continues its work, without waiting for a response. This is inherently non-blocking and a natural fit for distributed environments.
- Defined Behavior: In response to receiving a message, an actor can do one of three things: update its own private state, send messages to other actors, or create new actors.
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
subgraph "Actor A"
MailboxA[Mailbox]
StateA
BehaviorA
MailboxA --> BehaviorA
BehaviorA --> StateA
end
subgraph "Actor B"
MailboxB[Mailbox]
StateB
BehaviorB
MailboxB --> BehaviorB
BehaviorB --> StateB
end
subgraph "Actor C"
MailboxC[Mailbox]
StateC
BehaviorC
MailboxC --> BehaviorC
BehaviorC --> StateC
end
BehaviorA -- sends message --> MailboxB
BehaviorB -- sends message --> MailboxC
BehaviorC -- sends message --> MailboxA
class StateA,StateB,StateC main
style StateA fill:#bbf
style StateB fill:#bbf
style StateC fill:#bbf
The synergy with agentic AI is undeniable. Agents are autonomous entities (actors) with internal state (their beliefs, goals, and plans) that communicate with other agents to collaborate. Frameworks like Akka and languages like Erlang/Elixir have been built on the Actor Model for decades, proving its ability to power massively concurrent, fault-tolerant systems like WhatsApp and Discord.
ℹ️ Microsoft Orleans.
Another prominent framework built on the actor model is Microsoft Orleans. Initially developed by Microsoft Research, Orleans is designed for building distributed, high-scale computing applications in the .NET ecosystem. A key innovation in Orleans is the concept of virtual actors. Unlike traditional actors that must be explicitly created and managed, virtual actors are always considered to exist. They are automatically instantiated by the Orleans runtime on demand when a message is sent to them. This simplifies the programming model significantly, as developers don’t have to worry about the lifecycle management of actors. This makes Orleans particularly well-suited for applications with a large number of fine-grained, stateful objects, such as in gaming and IoT.
ℹ️ Go and Communicating Sequential Processes (CSP).
A notable alternative to the actor model is the Communicating Sequential Processes (CSP) model, which is a cornerstone of the Go programming language’s concurrency primitives. Instead of actors, Go uses goroutines (lightweight threads managed by the Go runtime) and channels. In CSP, goroutines communicate by sending messages through channels. Unlike the actor model where messages are sent directly to an actor’s mailbox, in CSP, channels themselves are the communication primitive. One goroutine writes a message to a channel, and another goroutine reads from that channel. This decoupling of sender and receiver can lead to different and sometimes more flexible communication patterns. While the actor model emphasizes “sending a message to an actor,” CSP emphasizes “sending a value on a channel.” This fundamental difference in approach provides developers with another powerful tool for building highly concurrent applications.
At this point, you might be wondering how the Actor Model relates to the event-driven architecture I advocated for earlier. They sound similar. Do they compete? The answer is no. They are not competing patterns; they are complementary layers of a complete architecture.
Think of it this way:
- The Actor Model is the micro-architecture. It governs the behavior and interaction of individual computational units – the agents themselves. It provides a robust model for managing concurrency and state isolation within a service or a closely-related group of agents running in the same process or cluster. It answers the question: “How does this single agent process its work and talk to its direct peers without causing chaos?”.
- Event-Driven Architecture (using a durable message broker like Kafka) is the macro-architecture. It provides the persistent, reliable, and decoupled communication backbone between different groups of agents or different bounded contexts across the enterprise. It answers the question: “How do we guarantee that a message from the ‘Claims Processing’ swarm gets to the ‘Fraud Detection’ swarm, even if the fraud system is down for maintenance for three hours?”.
The most robust architecture uses both. You build your individual agents using the Actor model for safe, high-performance concurrency. These actors then communicate with the wider enterprise ecosystem by producing and consuming events from a durable event streaming platform. The Actor Model handles the real-time, in-memory concurrency, while the event bus handles the large-scale, asynchronous, and persistent cross-system communication.
Macro-Architecture (Cross-Service Communication)
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
ServiceA
ServiceB
EventBus
ServiceA -- Publishes/Consumes Events --> EventBus
ServiceB -- Publishes/Consumes Events --> EventBus
class EventBus main
Micro-Architecture (Intra-Service Concurrency)
---
config:
theme: "base"
---
graph TD
classDef main stroke:#233256,stroke-width:2px;
subgraph "Inside Service A"
Agent1["Agent (Actor 1)"]
Agent2["Agent (Actor 2)"]
Agent3["Agent (Actor 3)"]
Agent1 -- Asynchronous Message --> Agent2
Agent2 -- Asynchronous Message --> Agent3
end
4. Managing the Challenge: Taming the Autonomous Swarm
We can design the most elegant, resilient, and scalable agentic system in the world, but if we can’t govern it, it will never see the light of day in a regulated enterprise. Without robust, auditable, and secure governance, a system of autonomous agents is not a business asset; it’s an unacceptable liability. The key challenges that keep CTOs and Chief Risk Officers awake at night are non-negotiable table stakes.
- Security and Access Control: An agent is a powerful entity that can act on data and systems. How do we enforce the principle of least privilege? How do we ensure a marketing analytics agent can’t access sensitive HR data or, worse, call a financial transaction API? An agent with overly broad permissions is a gaping security hole waiting to be exploited.
- Cost Control: LLM inference is not free. A simple “runaway agent” – one caught in a logic loop, or a pair of agents endlessly debating a topic – could rack up a six- or seven-figure cloud bill in a matter of hours. We need hard guardrails to prevent this.
- Auditability and Explainability: When an agent makes a critical decision – denying a claim, approving a loan, flagging a transaction – we must be able to trace back the “why.” We need a complete, immutable log of its inputs, its reasoning process, and the actions it took. This is immensely challenging in a decentralized system of non-deterministic “black box” models.
- Data Privacy: Agents operating across system boundaries must be prevented from inadvertently leaking Personally Identifiable Information (PII) or other sensitive corporate data.
These challenges demand a governance framework that is built into the architecture from the very beginning. A compelling blueprint for such a framework is described in the research paper on SAGA: a Security Architecture for Governing Agentic systems. While a research concept, its core components are precisely what a real-world enterprise solution would require:
- A Centralized Provider: This is a trusted, authoritative service that acts as the identity and registry for all agents in the ecosystem. Users must authenticate to the Provider to register new agents. This prevents unauthorized or “shadow” agents from running and provides a defense against Sybil attacks where an attacker tries to overwhelm the system with malicious agents.
- User-Defined Policies: The agent’s owner – the enterprise – defines its access control policies. These policies dictate which other agents it is allowed to communicate with and what tools it is allowed to use. This puts control firmly back in the hands of the organization, moving from a model of implicit trust to explicit, policy-based permission.
- Cryptographic Access Tokens: Inter-agent communication is not a free-for-all. It is governed by short-lived, cryptographically-secured access tokens issued by the Provider. An agent must present a valid token to communicate with another. This dramatically limits the window of vulnerability; if an agent is compromised, its ability to do harm is constrained by the scope and lifetime of its current tokens.
---
config:
theme: "base"
---
sequenceDiagram
autonumber
participant User
participant AgentB as Initiating Agent
participant Provider
participant AgentA as Target Agent
User->>+Provider: 1. Register Agent A (with policies)
Provider-->>-User: Registration Confirmation
AgentB->>+Provider: 2. Request to contact Agent A
Provider->>Provider: Verify Agent B is in Agent A's policy
Provider-->>-AgentB: 3. Return Agent A info + One-Time Key (OTK)
AgentB->>+AgentA: 4. Initiate TLS connection & send OTK
AgentA->>AgentA: Verify OTK & derive shared key
AgentA-->>-AgentB: 5. Return encrypted Access Control Token (ACT)
loop Secure Communication
AgentB->>AgentA: 6. Request with ACT
AgentA->>AgentA: Verify ACT (expiration, quota)
AgentA-->>AgentB: Response
end
Many proof-of-concepts for agentic AI that I see today conveniently ignore these governance issues. This is a critical mistake. The very autonomy that makes agents powerful also makes them dangerous. A security vulnerability in a traditional application might lead to a data leak. A vulnerability in an autonomous agent can lead to that agent acting on compromised data, propagating damage across every system it’s integrated with.
For this reason, governance cannot be an afterthought. You cannot “bolt on” security and auditability to a pre-existing swarm of autonomous agents. The architecture for governance – the identity provider, the policy engine, the secure communication channels, the audit log – must be designed and built before the first agent is deployed into a production-connected environment. The “Provider” in the SAGA model is not just another component; it is the foundational control plane for the entire agentic ecosystem. Without it, you are not building an intelligent automation platform; you are building an ungovernable, untrustworthy, and ultimately unacceptable risk.
5. An Architect’s Closing Thoughts
The journey into agentic AI is exhilarating, but we must walk it with our eyes wide open. The promise of autonomous systems that can reason, adapt, and execute complex tasks is immense, but its realization will not be delivered by bigger LLMs or more clever prompts. It will be delivered through the disciplined, rigorous application of distributed systems architecture.
We’ve walked through the critical architectural pillars required to move from a demo to a durable enterprise system. We’ve seen that we must choose our collaboration patterns – from simple chains to complex orchestrations – with a clear understanding of their trade-offs in complexity, scalability, and control. We’ve recognized that an agent’s state is not a simple thing, and our data architecture must embrace a hybrid model that respects the different consistency guarantees demanded by the CAP theorem. We’ve learned that to build resilient workflows that can survive the non-deterministic failures of agents, we must adopt and adapt the Saga pattern for semantic compensation. We’ve identified the Actor Model as the ideal micro-architecture for managing concurrency, working in concert with an event-driven macro-architecture for large-scale communication.
And finally, and most importantly, we have established that governance is not a feature but a prerequisite. A foundational control plane for identity, policy, and auditing must be in place from day one.
My closing message to my fellow architects is this: the path to production-grade agentic AI is paved with the hard-won lessons of the past three decades of distributed computing. Our experience is more valuable now than ever.
- Start with the architecture, not the prompt.
- Treat agents as what they are: non-deterministic, stateful, concurrent distributed components.
- Prioritize your state management strategy (CAP), your fault tolerance model (Saga), your concurrency model (Actor), and your governance framework from the outset.
The Large Language Model is just the reasoning engine. It’s a powerful, revolutionary component, but it is still just one component in a much larger, more complex, and more challenging machine – a machine that we, as architects, are now responsible for building.
Let’s get to work.
Reference materials
- CAP theorem
- Actor model
- Akka
- Microsoft Orleans
- Communicating sequential processes
- [Paper] SAGA: A Security Architecture for Governing AI Agentic Systems
Thank you!


