




The focus of enterprise Artificial Intelligence has undergone a significant maturation, evolving beyond the selection and fine-tuning of individual models. The new frontier is the architectural design of comprehensive, integrated, and governed AI-native systems. For solution and enterprise architects, the most pressing challenges and opportunities no longer lie in the nuances of a single algorithm but in the orchestration, security, and operationalization of these complex, interconnected systems. This shift from a model-centric to a system-centric paradigm is driven by a confluence of powerful technological trends that are reshaping the modern AI stack.
ℹ️ Welcome to Agentic AI Digest
– collection of blog posts – your regular source for in-depth insights into the evolving Agentic AI industry.
Preface
In this blog post I analyze three macro-trends that form the foundation of this architectural transformation:
- The Rise of Agentic Frameworks: The industry is transitioning from simple request-response interactions with models to sophisticated, multi-step, and tool-using autonomous agentic workflows. These systems can plan, reason, and interact with their environment to achieve complex goals, demanding a new class of architectural patterns.
- The Convergence of Data & AI Governance: Governance is being reimagined not as a post-facto compliance checklist but as a foundational, automated fabric woven directly into the data and AI lifecycle. This integration is becoming a prerequisite for building scalable and trustworthy AI.
- The Blurring of Data Planes: The traditional, rigid boundaries separating operational/transactional (OLTP) and analytical (OLAP) data systems are collapsing, driven by the need for real-time intelligence and action in AI-native applications.
In this new landscape, the modern architect is the central figure responsible for synthesizing these disparate trends into a coherent, resilient, and value-generating enterprise platform. This analysis identifies five deep technical content opportunities that emerge from these shifts, providing architects with the necessary insights to navigate and lead this transformation.
1. Architecting the Agentic Enterprise: Beyond the Monolithic Model
The Shift from AI Features to AI Agents
A fundamental architectural evolution is underway, moving from embedding discrete AI “features” (e.g., a text summarization API call) into applications to designing holistic AI “agents.” An agentic system is defined by its capacity to autonomously plan, utilize external tools, and execute multi-step tasks to achieve a high-level goal. Recent announcements from major technology providers indicate this concept is moving from academic research into the realm of enterprise-grade solutions. These frameworks are not merely for generating content but for systems designed to “deeply plan, analyze, and synthesize information” and “autonomously manage tasks that previously required distinct expertise”.
The Emergence of Enterprise-Grade Agent Frameworks
The development and offering of agentic capabilities by cloud providers signals a new level of maturity and a clear path toward production deployment for these advanced systems.
- Microsoft’s Deep Research in Azure AI Foundry Agent Service: Microsoft has unveiled an API and SDK-based service for building sophisticated research agents, built upon advanced OpenAI models. Its architecture follows a distinct, auditable workflow:
- 1) Intent Clarification, using models like GPT-4.1 or GPT-4o to scope the user’s query;
- 2) Web Grounding, leveraging Bing Search to gather recent, high-quality data, thereby mitigating hallucinations;
- 3) Deep Research Execution, where the specialized
o3-deep-researchmodel synthesizes information from all sources in a step-by-step reasoning process; - and 4) Transparent Reporting, generating a structured, auditable output complete with source citations. This provides a concrete architectural pattern for building transparent, high-stakes agents for domains like market analysis and competitive intelligence.
- IBM’s ITBench and AssetOpsBench: IBM’s introduction of new benchmarks for industrial and IT agents is a critical indicator of the technology’s maturation. The existence of a standardized evaluation framework like ITBench, which includes 94 real-world scenarios covering Site Reliability Engineering (SRE), FinOps, and compliance assessment, moves agent evaluation from subjective assessment to objective, scientific measurement. It provides an “open framework where users can see if their agents can solve problems efficiently,” enabling practitioners to validate their agents against complex, enterprise-relevant tasks.
- Google’s “Big Sleep” for Cybersecurity: This project serves as a prime example of a specialized, high-impact agent. “Big Sleep” combines Google’s threat intelligence with agentic search capabilities to proactively discover zero-day security vulnerabilities. Its discovery of the SQLite vulnerability (CVE-2025-6965) before it could be widely exploited represents a significant architectural shift in security operations – from a reactive posture to a predictive one.
Learn more:
- Introducing Deep Research in Azure AI Foundry Agent Service | Microsoft.
- AI agents have the potential to revolutionize work — and now you can measure if they actually are | IBM
- IBM’s new benchmark puts industrial agents to the test | IBM
- ITBench on GitHub | IBM
- [Paper] ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
- AssetOpsBench on GitHub | IBM
- A summer of security: empowering cyber defenders with AI | Google
- Project Zero | Google
The Rise of AgentOps as a New Architectural Discipline
The concurrent emergence of sophisticated agent-building services like Azure’s Deep Research and rigorous agent-evaluation benchmarks like IBM’s ITBench is not coincidental. This signals the birth of a new and necessary operational discipline: AgentOps. This discipline extends far beyond traditional MLOps. While MLOps is centered on the model lifecycle (training, versioning, deployment, monitoring), it is insufficient for the unique challenges posed by agentic systems. An agent’s execution path is dynamic and non-deterministic; it interacts with external systems via tools, and its potential for “rogue actions” is significantly higher than that of a simple predictive model.
Therefore, a new set of practices is required to manage the lifecycle of the entire agentic system. AgentOps must encompass the governance of the agent’s planning logic, the lifecycle management of its integrated tools and APIs, robust state management for long-running and multi-step tasks, granular cost attribution for complex workflows, and specialized observability to detect behavioral issues like goal-drifting, tool misuse, or hallucinated reasoning paths. Enterprise architecture teams currently focused on MLOps are likely unprepared for this paradigm shift, which requires a broader, system-level approach to design, deployment, and governance.
Architectural Blueprint for an Enterprise Agentic System
A reference architecture for a robust enterprise agentic system should incorporate several key components derived from these emerging frameworks:
- Intent Scoping Engine: A preliminary module, often leveraging a powerful LLM like GPT-4.1, to clarify ambiguous user prompts and define the precise scope of the task.
- Governed Tool & API Registry: A centralized and governed catalog of available tools that the agent can use, including internal APIs, databases, and external services.
- Planning & Orchestration Core: The agent’s “brain,” responsible for decomposing high-level goals into a sequence of executable steps and selecting the appropriate tools from the registry.
- Secure Execution Environment: A sandboxed or containerized environment where the agent can safely execute tool calls without compromising the broader system.
- State Management Database: A persistent store, such as a key-value or document database, to track the context, progress, and intermediate results of long-running, multi-step agent tasks.
- Observability & Audit Layer: A comprehensive logging mechanism that captures every agent decision, tool invocation, input, and output. This layer is critical for debugging, performance analysis, and ensuring the auditability and transparency required for enterprise compliance.
Table 1: Comparative Analysis of Emerging Enterprise Agentic AI Frameworks
| Framework / Service | Core Engine / Model | Key Architectural Pattern | Target Enterprise Domain | Evaluation & Validation Method |
|---|---|---|---|---|
| Microsoft Azure AI Foundry Agent Service | o3-deep-research | Multi-step Research Pipeline (Intent Scoping -> Grounding -> Synthesis -> Audit) | High-Stakes Business Research & Analysis | Auditable reports with citations |
| IBM ITBench/AssetOpsBench | Model Agnostic (Framework) | Real-World Task Simulation & Validation | IT Operations & Industrial Automation | ITBench & AssetOpsBench scorecards |
| Google “Big Sleep” Agent | Google DeepMind Models | Predictive Threat Hunting & Vulnerability Discovery | Cybersecurity Operations | Real-world vulnerability discovery (e.g., CVE-2025-6965) |
2. Designing for Specialized, High-Throughput AI
The Counter-Trend: Beyond Scaling Up
While massive, general-purpose foundation models continue to dominate headlines, a critical and pragmatic counter-trend is emerging: the development of hyper-efficient, smaller models engineered for specific, high-throughput, or resource-constrained enterprise tasks. For a significant portion of real-world use cases – such as on-device processing, real-time analytics in streaming pipelines, and cost-sensitive batch jobs – these smaller, specialized models represent a more architecturally sound and economically viable choice than their larger counterparts.
Case Study: Deconstructing Microsoft’s Phi-4-mini-flash-reasoning
Microsoft’s Phi-4-mini-flash-reasoning model is a marker for this “compression” trend, designed specifically to bring advanced reasoning capabilities to edge devices, mobile applications, and other environments with tight constraints on compute, memory, and latency.
- Architectural Innovation: The SambaY Architecture: The model’s efficiency stems from its novel “decoder-hybrid-decoder architecture,” named SambaY. This architecture is a significant technical innovation that moves beyond standard transformer designs.
- Gated Memory Unit (GMU): At the core of SambaY is the Gated Memory Unit, a mechanism for efficient representation sharing between layers that “drastically improves decoding efficiency”.
- Hybrid Decoder Design: The architecture ingeniously combines a self-decoder (using Mamba, a State Space Model, and Sliding Window Attention) with a cross-decoder that interleaves expensive cross-attention layers with the new, efficient GMUs. This hybrid approach achieves linear computation complexity during the prefill stage and significantly reduces the computational overhead of decoding.
- Performance Implications for Architects: The architectural innovations translate directly into tangible benefits. The model delivers up to 10 times higher throughput and a 2- to 3-times average reduction in latency compared to its predecessor, Phi-4-mini. Crucially, it achieves this performance while being deployable on a single GPU, making advanced reasoning accessible for a much wider range of use cases.
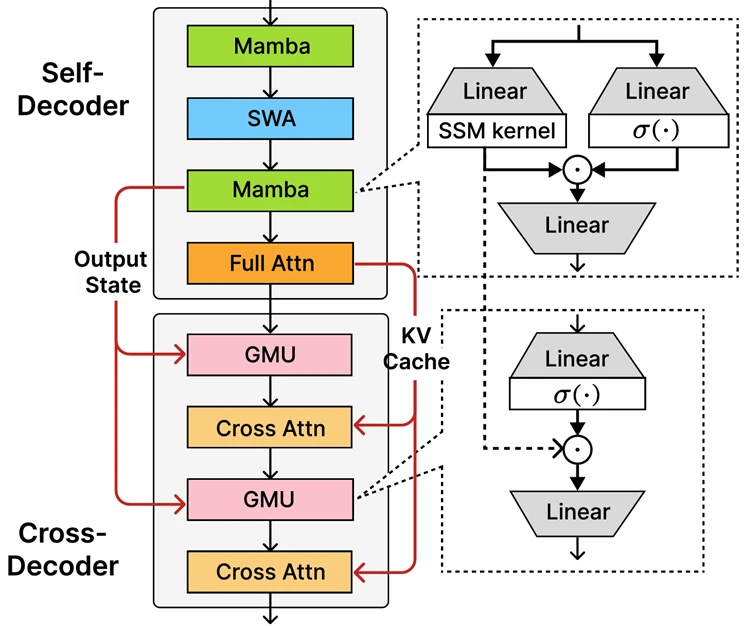
Model Specialization as a Driver of Architectural Divergence
The emergence of highly specialized model architectures like SambaY signals a fundamental divergence in AI system design. Enterprise architects can no longer rely on a single, monolithic “call the API” pattern for all use cases. Instead, they must now consciously design for at least two distinct architectural tracks:
- A “Maximalist” track for large, general-purpose models (e.g., GPT-4 series), which excels at complex, creative, or multi-domain tasks but comes with higher latency and cost.
- An “Optimized” track for specialized, efficient models (e.g., Phi-4-mini), which is ideal for high-volume, low-latency, or cost-sensitive tasks that operate within a well-defined domain.
The choice of track has profound implications for the entire system architecture. The pain point described by developers struggling with the complexity of AWS SageMaker Batch Transform for specific GPU and CUDA versions is a direct symptom of this divergence. Generic cloud platform abstractions often fail to keep pace with the rapidly evolving and highly specific hardware and software requirements of these optimized models. An architect who fails to distinguish between these tracks will design systems that are either dramatically underpowered for the task or catastrophically inefficient in terms of cost, performance, and user experience.
Design Patterns for Specialized AI Deployment
This architectural divergence necessitates distinct design patterns for deploying specialized models:
- Pattern 1: The Edge Inference Engine: An architecture for deploying models like Phi-4-mini directly onto edge devices such as industrial sensors or smart cameras. This pattern prioritizes model quantization, efficient runtimes (e.g., ONNX Runtime), and capabilities for offline operation.
- Pattern 2: The Real-Time Analytics Co-processor: An architecture for integrating specialized models into real-time streaming data pipelines (e.g., Apache Kafka, Flink). This pattern focuses on ultra-low-latency model serving and stateful feature computation to enrich data streams as they flow.
- Pattern 3: The Cost-Optimized Batch Transformer: An architecture for high-volume, non-real-time tasks like document classification or data extraction. This pattern focuses on maximizing GPU utilization and minimizing cost in services like AWS SageMaker Batch Transform by carefully matching specialized models to specific, optimized instance types and CUDA configurations, directly addressing the challenges highlighted by the developer community.
Table 2: Architectural Deep Dive: Microsoft Phi-4-mini-flash-reasoning
| Attribute | Specification |
|---|---|
| Model | Phi-4-mini-flash-reasoning |
| Parameter Size | 3.8 Billion |
| Context Length | 64K Tokens |
| Core Architecture | SambaY (Decoder-Hybrid-Decoder) |
| Key Innovation 1 | Gated Memory Unit (GMU) |
| Mechanism | Efficient representation sharing between layers for improved decoding efficiency |
| Key Innovation 2 | Hybrid Self/Cross-Decoder |
| Mechanism | Combines Mamba (State Space Model) and Sliding Window Attention with interleaved cross-attention to optimize prefill and decoding stages |
| Performance (Throughput) | Up to 10x higher than Phi-4-mini |
| Performance (Latency) | 2-3x average reduction |
| Ideal Deployment Scenario | Edge devices, mobile applications, real-time API services |
| Architectural Implication | Enables complex reasoning in latency-sensitive or resource-constrained environments previously limited to simpler, less capable models. Lowers Total Cost of Ownership (TCO) for dedicated, high-volume workloads due to single-GPU deployment feasibility. |
Learn more:
3. Implementing Unified Frameworks for Data and AI
The Evolution of Governance: From Checklist to Code
The velocity and scale of modern AI development render traditional, manual governance processes untenable. In the AI era, governance can no longer be a checklist managed by a committee; it must be automated, integrated, and enforced as code directly within the data and AI platform. Recent strategic announcements from platform providers like Databricks exemplify this critical shift, moving governance from a peripheral concern to a core architectural component.
Deconstructing the Databricks AI Governance Framework (DAGF)
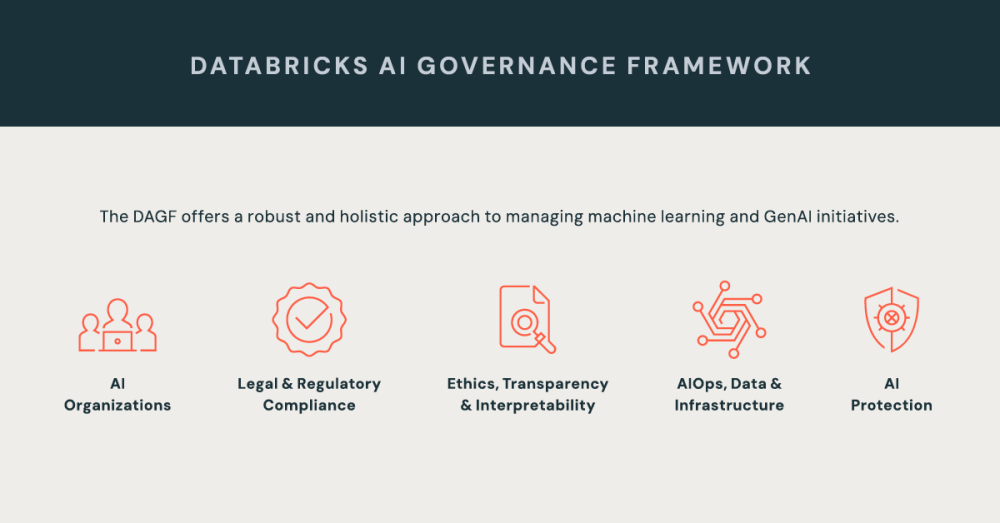


Databricks AI Governance Framework (DAGF). Source: https://www.databricks.com/blog/introducing-databricks-ai-governance-framework
Databricks has introduced the AI Governance Framework (DAGF) v1.0, a comprehensive blueprint for establishing and operationalizing enterprise AI governance. This framework is structured around five foundational pillars that provide a holistic approach:
- Pillar I: AI Organization: Focuses on embedding AI governance within the broader corporate strategy, defining clear business objectives, and establishing the necessary oversight structures and roles.
- Pillar II: Legal and Regulatory Compliance: Provides guidance for aligning AI initiatives with applicable laws (e.g., GDPR), managing legal risks, and adapting to the evolving regulatory landscape.
- Pillar III: Ethics, Transparency, and Interpretability: Emphasizes the principles required to build trustworthy AI, including fairness, accountability, human oversight, and explainability.
- Pillar IV: Data, AI Ops, and Infrastructure: Defines the technical foundation for reliable AI, covering the machine learning lifecycle, data quality, security, and operational best practices for models.
- Pillar V: AI Security: Introduces the Databricks AI Security Framework (DASF) to systematically identify and mitigate security risks across the entire AI lifecycle, from data protection to secure model serving.
Unity Catalog as the Technical Enforcement Layer
For an architect, the DAGF defines what needs to be done, while a platform like Databricks Unity Catalog provides how it gets done. Unity Catalog serves as the technical enforcement layer, with specific features that provide the underpinnings for the DAGF’s principles.
- Unified Governance: Unity Catalog offers a single, centralized control plane for all data and AI assets. This includes structured data (tables), unstructured data (Volumes), machine learning models, AI agents, and dashboards. This directly implements the “unified management” best practice of centralizing metadata for all assets in one place.
- Fine-Grained Access Control: The framework’s security and compliance pillars are enforced through Unity Catalog’s hierarchical privilege model. This enables attribute-based access control (ABAC), row- and column-level security, and dynamic data masking, allowing policies to be applied consistently to protect sensitive data like PII.
- Automated Lineage and Auditing: To meet the demands for transparency and interpretability, Unity Catalog automatically captures and visualizes end-to-end data lineage across pipelines, tables, models, and dashboards.Furthermore, all access and operations are captured in detailed audit logs, which are queryable via system tables. This auditability is foundational for compliance and for building operational tools like the Model Serving Cost Attribution Dashboard, which provides FinOps governance.
- Federated Governance: The governance fabric is not confined to data within Databricks. Unity Catalog can extend its governance to external data sources, including SAP, Snowflake, and Google BigQuery, allowing a single set of policies to be applied across a heterogeneous enterprise data landscape.
Governance as a Prerequisite for AI Scalability and Trust
The intense industry focus on creating comprehensive, integrated governance frameworks like DAGF and enforcement platforms like Unity Catalog is not accidental. It is a direct and necessary response to the risks, compliance failures, and spiraling costs of early, ungoverned enterprise AI projects. The market has reached a crucial inflection point: without a robust, automated governance fabric, AI initiatives cannot scale, will inevitably fail security and regulatory audits, and will ultimately lose the trust of the business.
This represents a fundamental reordering of priorities for enterprise architects. Designing the governance architecture is no longer a secondary task to be addressed before a go-live date; it is now the primary enabling architecture that must be designed first. It is the foundational layer upon which all scalable, secure, and trustworthy AI applications must be built. The “move fast and break things” phase of enterprise AI is over. The initial question for any new AI project must shift from “Let’s build a RAG prototype” to “What is our governance framework, and how will we technically enforce access control, lineage, and auditability for the entire lifecycle of this system?”
Table 3: Mapping the Databricks AI Governance Framework (DAGF) to Architectural Implementation
| DAGF Pillar | Architectural Concern | Unity Catalog Implementation |
|---|---|---|
| AI Organization | Centralized Asset Management & Discovery | Unified catalog for tables, files, models, notebooks, and dashboards. AI-powered documentation and search. |
| Legal & Regulatory Compliance | Policy Enforcement for PII & Sensitive Data | Attribute-Based Access Control (ABAC), column/row-level security, and dynamic data masking for compliance with regulations like GDPR. |
| Ethics, Transparency & Interpretability | End-to-End Traceability & Auditability | Automated, table- and column-level data lineage capture across pipelines and dashboards. Queryable audit logs via system.access tables. |
| Data, AIOps & Infrastructure | Data & Model Quality Assurance | Automated data quality monitoring with proactive alerts. Centralized Model Registry for versioning and lifecycle management. |
| AI Security | Secure Access to All Data & AI Assets | Hierarchical privilege model for fine-grained permissions. Native integration with identity providers like Microsoft Entra ID. |
Learn more:
- Introducing the Databricks AI Governance Framework | Databricks
- Best practices for data and AI governance | Microsoft
- Data governance with Azure Databricks | Microsoft
- Unity Catalog - Unified and open governance for data and AI | Databricks
4. The Convergence of Transactional and Analytical Data Planes
The Traditional Divide: OLTP vs. OLAP
For decades, data architecture has been defined by a fundamental separation between two types of systems. On one side, Online Transaction Processing (OLTP) databases (e.g., Postgres, MySQL) are optimized for fast, concurrent writes and simple lookups, powering operational applications. On the other, Online Analytical Processing (OLAP) systems (data warehouses and data lakes) are optimized for large-scale reads and complex queries, powering business intelligence and analytics. This bifurcation, while stable, introduces inherent latency and complexity, as data must be periodically moved from OLTP to OLAP systems via Extract, Transform, Load (ETL) processes.
The Driver: AI-Native Applications
This traditional architecture is fundamentally incompatible with the demands of real-time, AI-native applications. These applications, particularly autonomous agents, require a continuous, low-latency feedback loop: an action occurs in an operational system, the resulting data must be immediately available for model inference, the model’s output then triggers a new action, and the cycle repeats in near-real-time. The batch-oriented delay of a traditional OLTP-ETL-OLAP pipeline breaks this essential loop. The new generation of architectures must be “built for AI,” not merely “support AI”.
The Architectural Shift: Integrating OLTP into the Lakehouse
A primary indicator of this architectural convergence is Databricks’ strategic move to acquire Neon, a company specializing in serverless Postgres. This is not simply adding another data connector; it is a deliberate strategy to integrate OLTP capabilities directly into the core of the lakehouse platform.
- Neon’s Enabling Architecture: Neon’s design is uniquely suited for this new paradigm. Its serverless architecture, which decouples storage and compute, allows for the rapid, on-demand provisioning of thousands of isolated Postgres instances. This is a critical capability for AI agents, which may need to spin up ephemeral database environments for safe experimentation or parallel task execution.
- The Full-Stack AI Vision: This acquisition helps create a unified, full-stack development environment within a single platform: Neon for real-time transactional workloads, Delta Lake for large-scale analytical pipelines, and MosaicML for model training and fine-tuning. This convergence effectively blurs the lines that have long separated operational and analytical systems.
- Impact on AI Agent Workflows: Neon’s database features, such as instant branching and forking, are particularly valuable for agentic workflows. These capabilities allow an agent to “clone a full working dataset for safe experimentation” or to “backtrack and retry paths in multivariate execution trees,” enabling more robust, auditable, and safer agent execution pipelines.
The Lakehouse Evolves into the Intelligence Factory
The integration of true OLTP capabilities into the lakehouse architecture represents more than mere technical convergence. It marks the evolution of the data platform from a passive data repository – a “warehouse” or “lake” – into an active, operational “Intelligence Factory.” In this new architectural paradigm, the platform is no longer just a system of record for analyzing the past; it becomes a system of intelligence and action for the present.
This shift can be understood by considering the flow of work. In a traditional warehouse, data is ingested, processed, and stored, waiting to be queried for backward-looking insights. In an Intelligence Factory, real-time transactional data flows in as raw material onto a continuous assembly line of data pipelines and feature engineering. This refined data is then immediately consumed by intelligent machines – AI models and agents – that perform actions in the real world. These actions generate new transactional data, which instantly feeds back into the system, creating a virtuous, self-improving loop. This transforms the data platform’s role from a static archive into the dynamic, operational substrate for the intelligent enterprise.
Learn more:
- Databricks + Neon | Databricks
5. RAG Re-Architected: Advanced Retrieval Patterns for Complex Enterprise Data
Beyond Basic RAG: The Enterprise Reality
While the high-level concept of Retrieval-Augmented Generation (RAG) is straightforward, implementing it effectively within a corporate environment presents a formidable architectural challenge. Enterprise data is not a clean corpus of text files; it is a heterogeneous mix of structured databases, semi-structured reports, complex legal documents, and unstructured files. Basic RAG implementations that simply chunk text and query a vector database are insufficient for delivering the accuracy and reliability that businesses demand.
Deep Dive into Advanced RAG Techniques
Recent research, such as the work detailed in the paper “Advancing Retrieval-Augmented Generation for Structured Enterprise and Internal Data”, provides a technical guide for architects on the advanced patterns required for enterprise-grade RAG.
- Hybrid Retrieval: This architecture moves beyond pure vector search by combining dense (semantic) retrieval with sparse (keyword-based) methods like BM25. This ensures that the system can find documents that are contextually relevant (via semantics) while also precisely matching critical keywords, names, or product codes.
- Structure-Aware Chunking: Instead of naive, fixed-size chunking, this technique parses documents based on their intrinsic structure (e.g., sections, paragraphs, tables in a financial report). This preserves the semantic integrity of the content, preventing meaningful context from being split across disconnected chunks.
- Table-Specific RAG: This is a critical pattern for any enterprise. To handle tabular data effectively, the architecture must implement table-aware chunking and, crucially, individual row indexing. This granular approach allows the RAG system to answer highly specific, row-level queries (e.g., “What were the sales for product XYZ in Q2?”) that are impossible with standard text-chunking methods.
- Query Transformation & Refinement: This pattern introduces a preliminary step where the user’s initial query is passed to an LLM for rewriting and expansion. This process clarifies ambiguous language and adds relevant context before the retrieval stage, dramatically improving the quality of the documents fetched from the index.
- Cross-Encoder Reranking: After an initial set of candidate documents is retrieved, a more computationally intensive cross-encoder model is used to re-rank them. This second stage provides a more accurate assessment of relevance by jointly encoding the query and each document, ensuring the most pertinent information is passed to the final generation step.
- Grounded Prompting: To enhance trust and mitigate hallucinations, this prompting strategy explicitly instructs the generation model to anchor its response solely in the provided retrieved evidence. The architecture should also be designed to extract and present citations or summaries of the source documents alongside the generated answer.
RAG is Not a Feature, It’s a Data Engineering Discipline
The sophistication of these advanced patterns reveals a crucial truth for enterprise architects: successful RAG is not a simple “feature” to be activated by plugging a vector database into an LLM. It is a deeply integrated data engineering and architecture discipline. The ultimate performance of a RAG system is determined less by the choice of the final LLM and more by the quality and robustness of the “retrieval” pipeline. Building this pipeline is a classic data architecture challenge, involving complex data ingestion, transformation (chunking), storage (indexing), and federated querying.
This reframes the entire RAG initiative for enterprise leaders and architects. The teams best equipped to build state-of-the-art RAG systems are not solely AI specialists but experienced data architects and engineers who possess deep expertise in building scalable, reliable data pipelines. A project that begins with the question “Which LLM should we use?” is starting from the wrong place. The success of enterprise RAG hinges on excellence in data engineering, and the project should be treated as a data architecture initiative first and foremost.
LEarn more:
Key Findings: Strategic Recommendations for the AI-Centric Architect
The analysis of recent trends reveals a clear set of strategic imperatives for enterprise and solution architects aiming to build the next generation of AI-powered systems.
- Embrace System-Level Thinking: The architect’s primary role has shifted from integrating a single model to designing the entire, end-to-end intelligent system. This requires a holistic view that encompasses data pipelines, agentic orchestration, governance frameworks, and operational infrastructure.
- Build a Bifurcated AI Strategy: A one-size-fits-all approach to model deployment is no longer viable. Architects must design and maintain two distinct architectural tracks: a “Maximalist” track for leveraging large, powerful, general-purpose models via cloud APIs, and an “Optimized” track for deploying small, specialized, and efficient models for high-volume or low-latency tasks, often on custom-tuned infrastructure.
- Design Governance In, Not On: Automated, integrated governance is the critical enabler of scalable and trustworthy AI. The governance fabric, implemented through platforms like Databricks Unity Catalog, must be a day-one design consideration and a foundational element of the architecture, not a day-100 compliance task.
- Prepare for Data Plane Convergence: The traditional silos between OLTP and OLAP systems are breaking down. Architects must begin planning for this convergence by exploring architectures that support the real-time feedback loops required by AI-native applications, transforming the data platform from a passive repository into an active “Intelligence Factory.”
- Invest in Data Engineering for RAG: Reframe Retrieval-Augmented Generation as a core data architecture challenge. The success of enterprise RAG depends on the quality of the retrieval pipeline. Prioritize investment in the advanced data engineering skills needed to implement sophisticated patterns like hybrid retrieval and structure-aware chunking.
- Prioritize AgentOps: The emergence of enterprise-grade agentic frameworks necessitates a new operational discipline. Architects should advocate for and begin developing the practices of “AgentOps” to manage the unique lifecycle of autonomous systems, covering planning, tool integration, state management, and specialized observability, in preparation for the coming wave of enterprise agents.

Thank you!



